
CKAN is a popular data repository used by many Open Data projects and widely used in a number of Smart Cities. Here in Canada, we use CKAN as part of the Urban Opus data hub. The Urban Opus Smart City hub has been running for over 2 years. The details of its design can be found in the technical paper but it basically consists two core components, CKAN as a document repository and an IoT platform (WoTKit) used for time series data as shown below (right side).

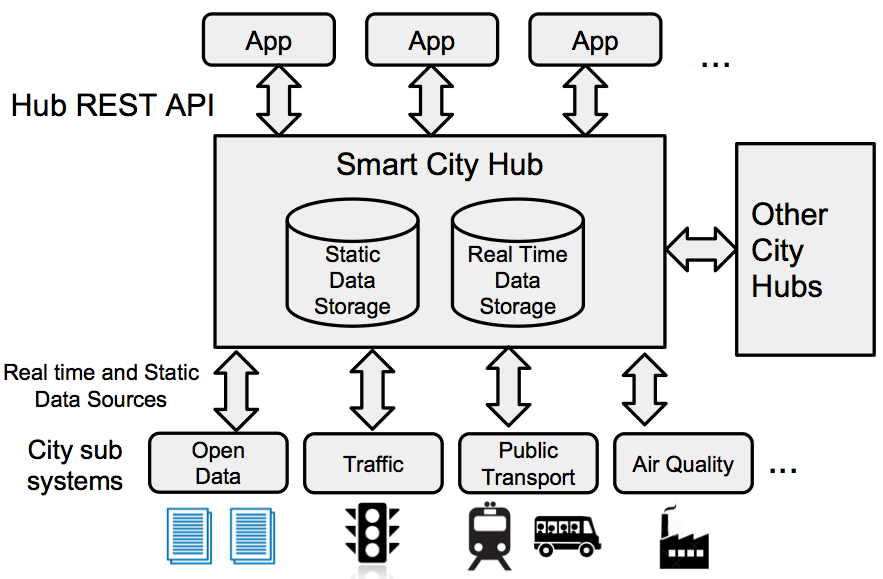 Typically – although not always – open data sets are static data, published infrequently and usually stored in a document store like CKAN’s FileStore. Real time city data, such as data from sensors, mobile phones, transportation etc, tends to be stored in a data base that is optimised for time series data.
Typically – although not always – open data sets are static data, published infrequently and usually stored in a document store like CKAN’s FileStore. Real time city data, such as data from sensors, mobile phones, transportation etc, tends to be stored in a data base that is optimised for time series data.
While we’ve been happy with this setup, there is a cost to maintaining and supporting our own bespoke CityHub and in particular, a full blown IoT platform. Recently we decided to investigate part of the CKAN platform that we haven’t used much – and which seems to be only lightly used by most use – the CKAN Datastore.
Filestore versus datastore – and handling real time city data
In contrast to the CKAN Filestore that handles files such as excel spreadsheets, pdfs, txt documents etc, the DataStore is a general purpose database with fine grained access. In the words of the CKAN developers:
“In contrast to the the FileStore which provides ‘blob’ storage of whole files with no way to access or query parts of that file, the DataStore is like a database in which individual data elements are accessible and queryable. To illustrate this distinction consider storing a spreadsheet file like a CSV or Excel document. In the FileStore this filed would be stored directly. To access it you would download the file as a whole. By contrast, if the spreadsheet data is stored in the DataStore one would be able to access individual spreadsheet rows via a simple web-api as well as being able to make queries over the spreadsheet contents.”
While it’s clear that the datastore can be used to store and access fine grained data, such as individual 311 records, like most traditional databases it is not optimised for time series data, i.e. data that is arriving in quasi realtime and is constantly updated. For example the real-time location of a bus or the electricity usage of city hall.
Is the CKAN datastore sufficiently performant for time series data needs
Our goal was to understand the performance of the CKAN datastore running on a small server machine and to see if we could we use it to replace our highly optimised IoT platform.
To do that, we decided to run a series of performance tests using the CKAN datastore web API looking how it performed with a variety of client loads and against both small and large databases. For all tests, we used the same small server: Desktop server running Ubuntu 16.04, Intel Core i5, 8GB RAM, 10MB/s bandwidth.
These tests were carried out by Nam Giang, a PhD candidate at the university of British Columbia (Dept of ECE). We acknowledge his hard work and useful insights.
Test 1: Query data from a small table
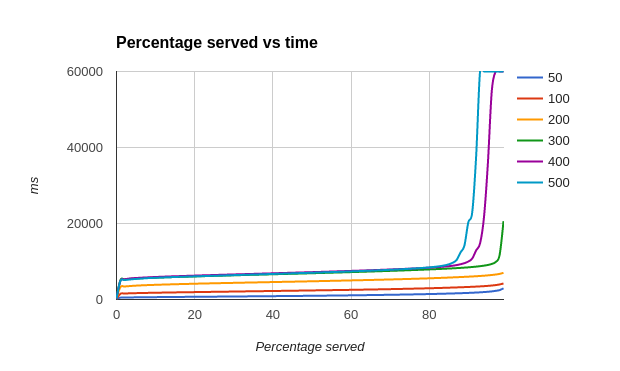
The first test performs a simple query to look for 10 records in the table corresponding to ten timestamped sensor readings. We increased the number of clients – all making simultaneous request – from 50 to 500 and looked at the average response time.
As can be seen in the graph below, on average, about 80% of the requests are performed within 10 seconds (10,000 milliseconds) but under high load, eg 3-500 simultaneous clients, some requests could take upto a minute.
Looking at the overall server performance, we plot the requests handled per second under the different loads. Again, we can see an average of approximately 40 requests per second on our server.
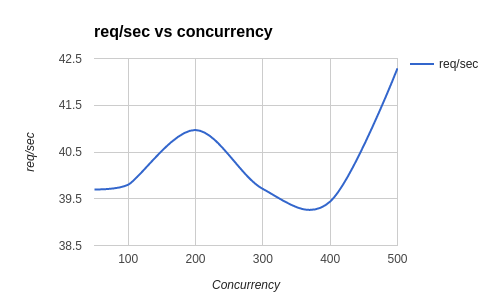 the server can handle about 42 requests per second.
the server can handle about 42 requests per second.
Total requests: 50,000
Maximum simultaneous clients: 500
Test api: /api/3/action/datastore_search?resource_id=<id>&limit=10&offset=5354 Table size: 140604 rows
Test 2: Query data from a large table
In the previous test, we were using a relatively small table (approx 140,000 rows) which is really only even for a day and a halfs data from a sensor sending data every second. A more reasonable table size would be a million rows. However this is a far larger table and is likely to have a performance effect. To understand that we ran the same tests but with the bigger table.
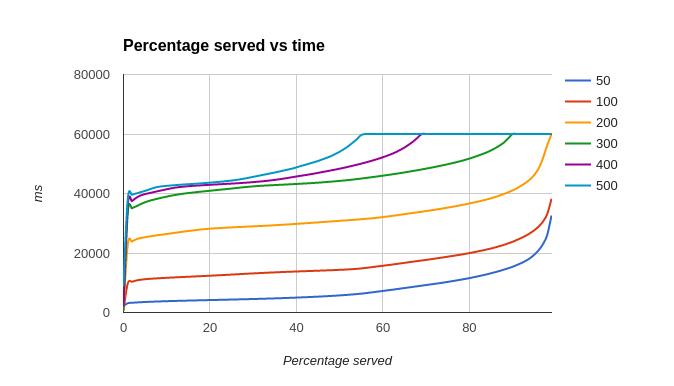
As can be seen, the performance when the table is large is markedly different (and quite poor). As can be seen in the worst case of 500 simultaneous clients, about 20% of requests sent are responded to within 20s, but about 40% of requests time-out (60s); the server can handle about 9 requests per second (graph below)
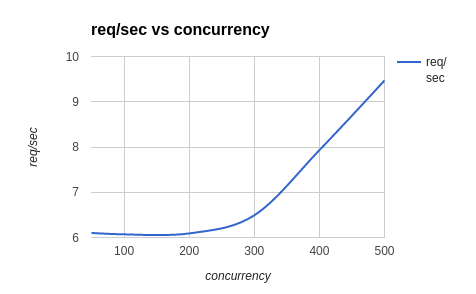
Total requests: 50,000
Maximum simultaneous clients: 500
Test api: /api/3/action/datastore_search?resource_id=<id>&limit=10&offset=5354 Table size: ~1 million rows
Test 3: Comparing a variety of requests made to the CKAN server.
For our final test, we wanted to understand the performance of the DataStore when it has a variety of different requests. Remember in the tests above, all clients are reading data – which is probably not a realistic scenario. In this test we mix up the rquests and include inserts, web access and read requests.
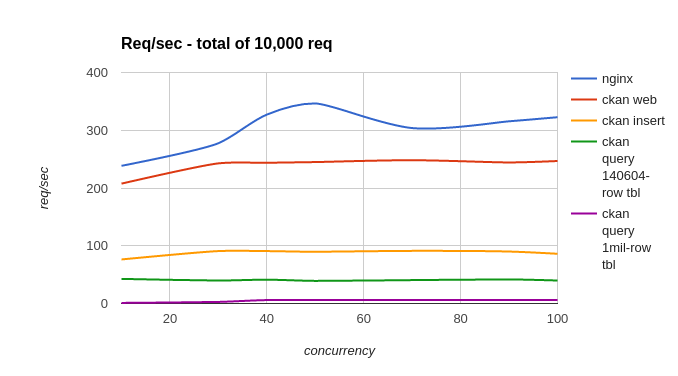 Total: 10,000
Total: 10,000
As can be seen, for each of the tests actions:
- Bare nginx reverse proxy server: approx 300 req/sec – which can be considered a benchmark for the server
- Ckan web stack: send a malformed query so that no database access incurred: approx 250 req/sec
- Inserting data to CKAN datastore: approx 80 reqs/sec
- Querying data from a small datastore table: approx 45 req/sec
- Querying data from a large datastore table: approx 10 req/sec
The details of this test are:
request
Maximum simultaneous clients: 100
CKAN web api: /api/3/action/datastore_search CKAN insert api: /api/3/action/datastore_upsert data: {“resource_id”: “<id>”, “method”:”insert”, “records”: [ { “temp”: 1, “humid”: 2}, {“temp”: 3, “humid”: 4} ]}
CKAN query api: /api/3/action/datastore_search?resource_id=<id>&limit=10&offset=5354
Observations and Conclusion
Generally, the server performs well with data write requests with about 100 requests per second capability.
For data read requests, there is a significant degradation in performance with regard the size of the data table. Specifically, for a table of size 140,000 rows the server can handle about 40 requests per second. The performance plummets to about 10 requests per second for a table of size 1 million rows.
This performance is somewhat strange, read operations are generally quite lightweight and should be less costly than write (insert) however we can see from the above that read requests are very slow. Since the CKAN datastore is based on the PostgreSQL database, we were puzzled by these performance figures. They indicate that CKAN imposes an overhead, that at times is significant, and that traditional data read and write performance seems to be inverted.
To understand this better we took a look at the CKAn datastore code to try and determine what it did with API calls before it actually called into the PostgreSQL database.
What we found was that when the CKAN Datastore processes the requests made through the “datastore_search” API, it add a count(*) to the generated query to return the number of rows in the table. If we bypass this behaviour and use the native SQL API – “datastore_search_sql”, then it’s much faster because we provide our own query. In general, a request falls from 400ms to approx 90ms – which is closer to the raw performance we expect from PostgreSQL.
Our next step is to improve this performance to get closer to the raw SQL performance of PostgreSQL by optimising the CKAN datastore API. To do this, we plan to rewrite the code and offer it as new plug-in for CKAN.